
Automated actions to manage all your unreliable tests
Identify unreliable tests, quarantine or rerun them. Create automatic JIRA tickets, set up alerts, assign owners from a single dashboard.
Read the docs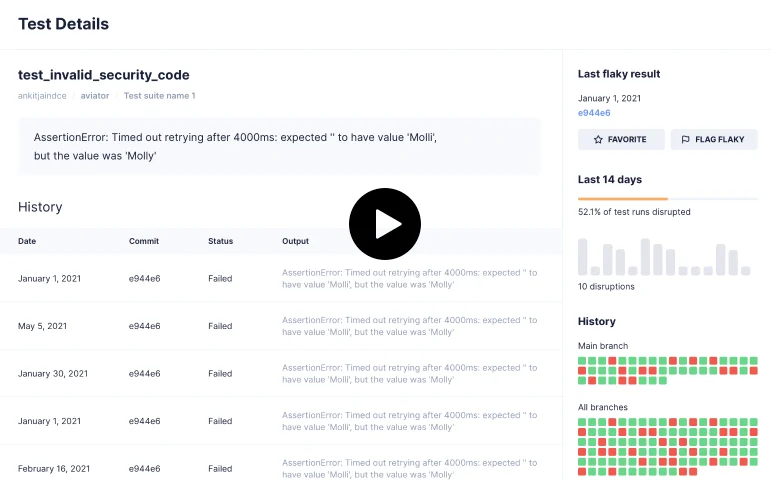

TestDeck provides historical data at individual test case level. Using TestDeck you can easily pinpoint the most unreliable test cases and take action on them.



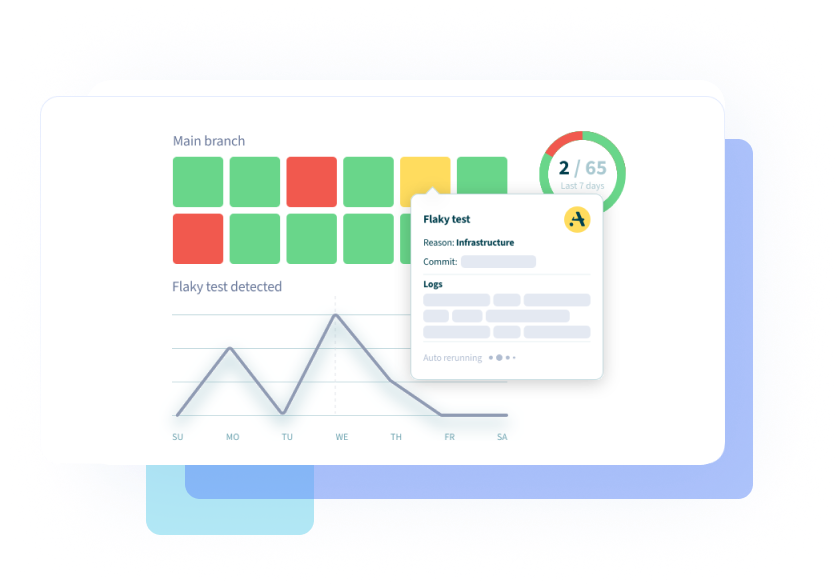
Using Aviator’s test plugin, you can control the test execution directly from the dashboard. You can specify the auto-quarantining criteria, or a criteria to auto-rerun any test.
Use TestDeck APIs and webhooks to configure your custom workflows. Create a JIRA ticket or assign owners. TestDeck also provides test health summary using Slack notification.


We support all major CI providers including CircleCI, Buildkite, Github Actions and Jenkins. Simple use one of our custom CI plugins to set up TestDeck within 5 mins.
Configure nightly jobs that automatically rerun the tests to identify flaky behavior proactively while you sleep.

SOC 2 is a deep-dive audit, delivered in a final report, based on AICPA’s existing Trust Services principles and criteria. Aviator has completed a SOC 2 audit evaluated on information systems relevant to security, availability and confidentiality. Need a copy? Email: sales@aviator.co

